

in English
en français
magyar nyelven
- Was ist das FactGrid?
- Warum sollte ich das FactGrid für die eigene Forschung benutzen?
- Warum nicht gleich Wikidata benutzen?
- Das FactGrid kommt kostenfrei – wie geht das an?
- Was mache ich mit unorthodoxen Forschungsanliegen?
- Welche Tools stellt die Software mir zur Verfügung
- Was mache ich, wenn ich ganz eigene Datendarstellungen auf meiner eigenen Plattform realisieren will?
- Das FactGrid lizenziert Daten grundsätzlich CC0 – heißt das nicht, dass ich alle Rechte an meiner Forschung aufgebe?
- Was geschieht, wenn ich mit meinen Daten auf einer anderen Plattform weiterarbeiten will?
- Was passiert, wenn es zwischen FactGrid-Benutzern zum Streit über ein “korrektes” Datum kommt?
- Warum sollte ich in meinem Projekt Transparenz schon von Anfang an riskieren?
- Wie nutze ich das FactGrid konkret?
Was ist das FactGrid?
Das FactGrid ist eine Wikibase-Instanz, die, vom Forschungszentrum Gotha aus organisiert, an der Universität Erfurt gehostet wird.
Wikibase ist die Software, die hinter Wikidata läuft. Die Instanz will historischer Forschung einen eigenen Freiraum zur Verfügung stellen und im Verlauf technisch in der Lage sein, mit der GND und mit Wikidata laufend Daten auszutauschen — Daten, die aus dem FactGrid heraus international als Forschungsdaten zitierbar werden. Seit dem 5. November 2022 ist das FactGrid — als global agierende Plattform — offizielles Repositorium im Spektrum der deutschen Nationalen Forschungsinfrastruktur, NFDI4Memory.
Sehen Sie hierzu auch den Beitrag zu den Zielerwägungen, den Barbara Fischer für die GND und Jens Ohlig für Wikimedia am 9. Mai 2019 im Wikimedia Blog veröffentlichten.
Warum sollte ich das FactGrid für die eigene Forschung benutzen?
Dafür spricht erstens die unschlagbar flexible Software, Wikibase, die wir im Pilotprojekt mit Wikimedia Deutschland bahnbrechend außerhalb ihres eigentlichen Orts, Wikidata, zum Laufen brachten:
- Sie suchen eine Software, die praktisch jede gängige Sprache spricht und in der sich Daten in jeder Sprache eingeben und in danach in beliebigen anderen Sprachen ausgeben lassen? Wikibase ist diese Software.
- Sie suchen eine Software, in der Sie ein ganzes Team transparent koordinieren können? In Wikibase ist das so einfach wie in der Wikipedia Software MediaWiki.
- Sie suchen eine Datenbank-Software, die alles kann, was Datenbanken der Digital Humanities normalerweise können: Netzwerkanalysen, Repräsentationen auf Landkarten, komplex verknüpfte Recherchen, Timeline-Darstellungen (in verschiedenen Datenformaten), und die sich dabei einem Umgang mit normalen Aussagen annähert? Wikibase ist diese Software.
- Sie haben Datenmengen aus vorheriger Forschung, auf die Sie aufbauen wollen? Wikibase erlaubt den großflächigen automatischen Input.
- Sie wollen sicherstellen, dass Ihre Daten nachnutzbar werden? Wikibase ist genau darauf eingestellt.
- Sie wollen neuartige Fragen an Material stellen? In Wikibase können Sie beliebige Objekte mit beliebigen Aussagen Ihres Interesses verknüpfen.
- Sie fragen sich, was nach Ihrer Projektlaufzeit mit Ihren Daten und Ihren Präsentationstools noch geschieht? Setzen Sie auf eine Plattform, auf der Sie nicht allein arbeiten und auf eine Datenlizenz, die es anderen ermöglicht, Ihre Arbeit wirklich risikolos zu nutzen und fortzuentwickeln!
Für das FactGrid spricht im selben Moment, dass wir im Interesse am breiten und offen bleibenden Datenaustausch in einer Kooperation mit der Deutschen Nationalbibliothek die gesamte Plattform soeben auf GND-Daten aufsetzen, um das Projekt in seiner größeren Breite in der entstehenden Landschaft von “Federated Wikibase Platforms” zu verankern.
Warum nicht gleich Wikidata benutzen?
Das ist eine gute Frage, die man sich stellen sollte. Es wird Projekte geben (die hauptsächlich Daten nutzen), für die Wikidata die bessere Plattform ist. Für die FH-Potsdam demonstrierte dies der „Archivführer zur deutschen Kolonialzeit“; wir sprachen darüber mit Uwe Jung, der die technischen Lösungen vorstellte, die man dort realisierte.
Zwei Dinge, gibt es, die es andererseits interessant machen, gezielt eine (Wikidata und die GND beliefernde) eigene Plattform aufzubauen: Die Wikimedia- (und GND–) spezifische “No Original Research” Grundregel und die fundamentale Entscheidung für Relevanzkriterien auf beiden Plattformen, die das beliebige Aufmachen von Datenbankobjekten und Objektbeziehungen ausschließt.
Wikidata und die GND richten sich auf bereits publizierte Information aus und auf Bearbeiter außerhalb der Forschung, die Publikationen auswerten und Daten eingeben. Unmöglich wird es bleiben, auf diesen Plattformen Arbeitshypothesen zu riskieren, Datierungen, die erst einmal auf Probe gestellt sind, Personeninformationen, die später in einer Publikation nur statistisch ausgewertet werden sollen.
Im FactGrid ermuntern wir zur Nutzung der Plattform als heuristischem Forschungstool.
- Legen Sie hier Datenbankobjekte an, die Sie weit später erst auswerten wollen, egal welche Relevanz diese in einer Enzyklopädie oder in Bibliothekskatalogen gewinnen können.
- Riskieren Sie provisorische Datierungen – als Arbeitshypothesen zusammen mit Ihren persönlichen Annahmegründen.
- Wagen Sie im FactGrid unkonventionelle Aussagen, die erst einmal nur in Ihrem Forschungsprojekt interessant sind – die Software erlaubt es Ihnen.
- Bauen Sie eigene Datenbankobjekte zu Ihren Forschungsprojekten und verknüpfen Sie diese mit allen Datenbankobjekten, an denen Sie arbeiteten, um so Ihrem Geldgebern die eigene Forschung im Paket der Datenbeziehungen vorlegen zu können.
- Riskieren Sie im FactGrid Thesen und führen Sie diese in der Datenbank als “Mikro-Publikationen” mit eigenen Datenbank Objekt-Nummern.
Das FactGrid kommt kostenfrei – wie geht das?
Die Software ist frei verfügbar und befindet sich in einer von großen Communities getriebener Entwicklung im Wikimedia-Bereich und in Zukunft in hinzukommenden Institutionen wie denen der europäischen Nationalbibliotheken, die soeben eigene Wikibase Instanzen und Tools bauen.
Das FactGrid selbst läuft unter Ägide des Forschungszentrums Gotha auf einem virtuellen Server der Universität Erfurt. Für die deutsche URL fallen jährlich €36 Domaingebühren an, die vom Forschungszentrum Gotha getragen werden.
Nutzern stehen alle Tools aus dem Wikidata Projekt zur Verfügung. Mit ihnen sind die Standardanwendungen gängiger Humanities Projekten erst einmal abgedeckt.
Da die Software open source ist, können Projekte eigene Software-Etats gezielt in Tools und Präsentationen investieren, um die es ihnen in der eigenen Forschung geht. Arbeiten Sie gerne mit einer favorisierten Softwareschmiede zusammen, so wird diese, was den Quellcode der laufenden Software anbetrifft, vor offenen Türen stehen. Bieten Sie Ihre eigenen Entwicklungen offen zur Weiterentwicklung an, und Sie können darauf vertrauen, dass Visualisierungen auch nach Ihrer Projektförderung noch fortentwickelt werden. Streben Sie dagegen eigene Softwarelösungen mit dem Ziel einer kommerziellen Vermarktung an, so bindet Ihnen die Software-Lizenz hier nicht die Hände: Sie erhalten die bestehenden Softwarelösungen frei und können eigene darauf aufbauenden Tools jederzeit kommerziell verwerten.
Was mache ich mit unorthodoxen Forschungsanliegen?
Wikibase ist bahnbrechend offen in den mit dieser Software möglich werdenden Datenbankanwendungen. Letztlich werden hier nur Beziehungen zwischen Q-Nummern hergestellt (respektive Beziehungen zwischen Q-Nummern und Daten, Q-Nummern und Raumkoordinaten, Q-Nummern und Mediendateien, Q-Nummern und Internetadressen).
Was das für Beziehungen sind, das ist für die Software irrelevant. Q1 – P1 – Q2 ist ein “Triple” und kann bedeuten “Johann Sebastian Bach (Q1) ist der Vater von (P1) Carl Philipp Emanuel Bach (Q2)”; es kann genauso gut bedeuten “Der Brief des Archivs X mit der Signatur YZ (Q1) notiert als Absendeort (P1) München (Q2)”
Q-Nummern können für alles nur Denkbare vergeben werden – Personen, Dokumente, Ereignisse, Ideen… Sie selbst legen fest, was für P-Nummern Sie definieren wollen, um Aussagen Ihres Interesses zu Ihren Datenbankobjekten zu treffen. Im System kristallisiert sich letztlich erst mit den Aussagen, die Sie zu Ihren Objekten treffen, heraus, welcher Art Objekte das sind. Das heißt: Sie benötigen kein Kategoriensystem, das Ihnen im Vorhinein klar sein muss, um mit der Datenbank zu arbeiten. Sie treffen Aussagen dann, wenn Sie sie plötzlich setzen wollen, und sehen zu, wie sich diese zu einer kritischen auswertbaren Masse akkumulieren.
Alle Aussagen lassen sich “qualifizieren” – “Johann Sebastian Bach (Q1) war verheiratet mit (P2) Maria Barbara Bach (Q2) mit Beginn am (P2) 7. Oktober 1707 (Datum) bis zum (P3) ca. 5. Juli 1720 (Datum).” Alle diese Aussagen lassen sich wiederum beliebig mit Quellenaussagen versehen – “das geht hervor aus (P4) dem Kirchenbuch von… (Q3)”, “das wird so behauptet in (P5) der Bach-Biographie XYZ (Q4)”.
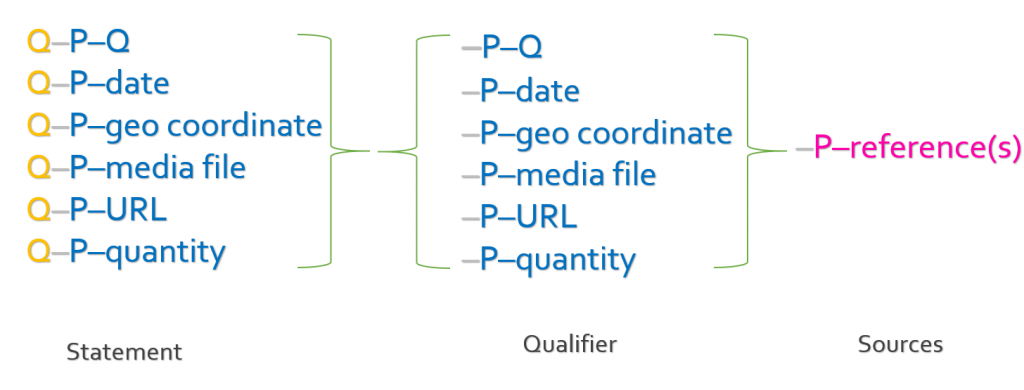
Das System lässt jederzeit konkurrierende Behauptungen zu. Sie werden einfach mit ihren unterschiedlichen Quellen eingebracht und können dabei beliebig untereinander bewertet werden. In ihrer weiteren Nutzung im System gewinnen sie ihre eigentliche Bedeutung.
Letztlich lassen sich auf damit beliebige normalsprachliche Aussagen generieren; vor allem aber öffnet dies die Tür in die Welt global handhabbarer Aussagen. Für das System spielen sich alle Aussagen nur als Verknüpfungen von Q-Nummern mittels P-Nummern ab. Sie selbst belegen die Q- und P-Nummern mit “Labeln” in den Sprachen, in denen Sie kommunizieren (Datums- und Mengenangaben verwaltet das System bereits in beliebigen globalen Standards mit automatischer Umrechnung in jede Richtung); so das Geheimnis, das es möglich macht, dass auf Wikibase Plattformen Autoren in ihrer jeweiligen Sprache eingeben und andere Nutzer diese Informationen in beliebigen Sprachen auslesen.

Welche Tools stellt die Software mir zur Verfügung
Datenbank-Eingaben können sukzessive erfolgen: Sie wollen über ein Objekt eine neue Aussage treffen? Rufen Sie das Objekt auf, gehen Sie ans Ende der Eingabe-Seite, wo “Aussage hinzufügen” steht, und beginnen Sie die Aussage in Ihrer Lieblingssprache – das System ergänzt mit Auto-Complete die gesuchte Aussage und sucht sich die P-Nummer dieser Aussage heraus. Tippen Sie in das sich nun eröffnende Feld ein, auf welches andere Objekt diese Aussage laufen soll oder auf welches Datum (in Ihrer Sprache) und die Software macht ihnen immer präzisere Vorschläge, noch während Sie tippen.
Datenbank-Eingaben können zweitens massenweise und automatisiert in gängigen Formaten aus Excel-Listen oder CSV-Listen erfolgen. (Dies ist die Eingabemaske und dies die kurze Anleitung dazu.)
Datenbankabfragen geschehen im Gegenzug mit “SPARQL“, eine Such-Sprache, die (leider) nicht einfach zu bedienen ist, die es jedoch nun erlaubt, die Datenbank beliebig komplex zu befragen – komplexer als jede Standard-Suchmaske Ihnen das erlauben würde. SPARQL-Nutzer müssen nicht unbedingt den SPARQL-Quellcode schreiben können. Man bedient sich in der Regel einer passenden Musterabfrage, die man in einer Sample-Queries-Liste findet, und tauscht hier die Suchbegriffe aus.
Weiß man exakt, welcher Art Suchanfragen Benutzer des eigenen Projektes durchführen können, so lassen sich Suchschablonen wie in herkömmlichen Katalogen bauen, die die Anfragen an das System unterhalb der Benutzeroberfläche in SPARQL formulieren.
Im Software-Paket finden sich Darstellungen auf Landkarten, Timelines, in Netzwerken, genealogischer Beziehungen, Diagramm-Darstellungen und so fort. Für diese Anwendungen müssen keine Softwarepakete eigens installiert werden. Sie formulieren in Ihrer SPARQL Anfrage, was für eine Darstellung Sie wünschen.
Einen sehr schönen Überblick über Visualisierungen gibt das Scholia Projekt auf der Wikidata Plattform.
Was mache ich, wenn ich ganz eigene Datendarstellungen auf meiner eigenen Plattform realisieren will?
Das sollte technisch kein Problem sein. Uwe Jung demonstrierte, wie eine Benutzeroberfläche der FH Potsdam Wikidata als Datenrepositorium benutzt, ohne dass die Benutzer mitbekommen, auf welche Repositorien die Abfragen zugreifen.
Nichts spricht dagegen, das FactGrid als ein externes Repositorium zu benutzen und das eigene Forschungsprojekt auf dem Server der Heimat-Uni aufzubauen und dort die Benutzer mit gezielten Datenbankzugriffen unter einer typischen Suchschablone zu bedienen.
Das FactGrid lizenziert Daten grundsätzlich CC0 – heißt das nicht, dass ich alle Rechte an meiner Forschung aufgebe?
Positiv gesprochen bedeutet die Entscheidung für die Creative-Commons-0-Lizenz, dass Sie die vollen Rechte an allen (Ihren) Daten behalten. Vor allem aber bedeutet die CC0-Lizenz, dass Ihre Daten frei nutzbar werden und damit weniger Gefahr laufen, als Forschung obsolet zu werden.
Einige grundsätzliche Erwägungen dazu: CC BY 4.0 ist auf den ersten Blick die Lizenz, die Wissenschaftlern näher liegt: Man gestattet die freie weitere Nutzung, wenn man dafür fachgerecht zitiert wird. In der Praxis lässt sich diese Lizenz bei Textveröffentlichungen (wie diesem Blogbeitrag) noch gut durchsetzen. Hier ist es klar, wie man den Text, den man verfasste, und Thesen, die man bahnbrechend formulierte, zitiert sehen möchte: Mit einem Verweis auf den eigenen Namen, mit dem Titel der Publikation, dem Publikationsort und dem Datum. Wie aber soll das Datenzitat (etwa die Information, dass ein Brief im Juni 1753 von Paris nach Berlin ging) innerhalb einer Visualisierung erfolgen, auf Strichen, die auf einer Landkarte erscheinen? Wie sollen Benutzer Datensätze zitieren, wenn diese nur zum Teil Informationen aus Ihrem Forschungsprojekt enthalten, zum größeren Teil jedoch andere Datenbankinformationen etwa aus einer öffentlichen Archivdatenbank bieten, die Sie einspielten? Noch größere Probleme stellen sich bei Daten mit Lizenzen, die eine “share-alike” Klausel bergen: “Diese Daten sind frei verfügbar, wenn die Nachnutzer sie genauso frei verfügbar halten.” Das klingt erst einmal nach nachdrücklicher freier Nutzung. Wie aber soll ein Nachnutzer sicherstellen, dass wiederum seine Nachnutzer sich an die von Ihnen gewünschte Lizenzvereinbarung halten (insbesondere, wenn dieser Nachnutzer auf CC0 geht)? Nachnutzer sind gut beraten, keine Daten aus CC-BY oder CC Share-Alike Lizenzen zu verwenden.
In der Praxis der größeren Kooperationen mit Wikidata und der Deutschen Nationalbibliothek kann es darum nur eine Option geben: Genauso frei Daten zur Verfügung zu stellen, wie die Kooperationspartner diese tun: CC0, das heißt ohne, dass sichergestellt wird, dass Nachnutzer noch exakt angeben, wer die Daten einzeln erhob, und was Drittnutzer wiederum mit diesen Daten tun dürfen.

Die maximal offene Lizenz heißt in der Praxis durchaus nicht, dass FactGrid Daten Daten ohne Autorschaft sind, ganz im Gegenteil. Wir legen es nahe, Forschung als Forschung zitierbar zu machen und gehen davon aus, dass Wikidata und die GND Zitiervoschläge gerne übernehmen. Alle Datensatzänderungen werden von der Software für alle Nutzer sichtbar an bei uns Real-namentlich gebunden. Haben Forschungsprojekte substanzieller an einem Datensatz gearbeitet, vermerken Sie dies jederzeit mit einer eigenen Notiz Ihrer Arbeit im Datensatz. Jeder kann die Datenbank danach befragen, welche Datensätze im Rahmen eines bestimmten Projektes bearbeitet wurden.
Tatsächlich ist es für Datenbanken wie Wikidata oder die Gemeinsame Normdatenbank der DNB, die GND, ungemein interessant, Daten aus dem FactGrid als dort erstmals publizierte zitieren zu können – es steigert die eigene Datensolidität, wenn sich Forschung benennen lässt und es gibt beiden Institutionen eine Plattform auf der möglich wird, was auf der eigenen Plattform ausgeschlossen bleibt.
Was geschieht, wenn ich mit meinen Daten auf einer anderen Plattform weiterarbeiten will?
Da Sie Ihre Daten ohne Copyright-Aufgabe einpflegten, können Sie sie in beliebig vielen anderen Projekten parallel laufen lassen. Wir sind hier gerne “nur” ein “Inkubator” für Forschungsdaten.
Was passiert, wenn es zwischen FactGrid-Benutzern zum Streit über ein “korrektes” Datum kommt?
Die Software lässt es zu, einander widersprechende Daten zu handhaben – das ist gerade im Feld der Geschichtswissenschaften interessant, wo wir oft dokumentarisch belegte divergierende Informationen haben, ohne noch ermessen zu können, welches die korrekte Aussage ist. Namen werden in verschiedenen Schreibungen gehandhabt; Geschichtsschreiber widersprechen einander.
Die Software erlaubt es, die widersprüchliche Lage abzubilden; sie erlaubt es, Objekte mit Dutzenden Namensschreibweisen zu belegen – es sind nur verschiedene Schreibweisen zu ein und derselben Q-Nummer.
Divergierende Aussagen lassen sich unterschiedlich einstufen – etwa als das derzeit autoritative Datum gegenüber Varianten, für die allein die verschiedenen einander widersprechenden Quellen sprechen.
Sollten zwei Forscher zu unterschiedlichen Befunden kommen, so ist das letztlich der Fall, auf den es jedes Projekt anlegen sollte. Das viel größere Risiko ist die hypothetische Entscheidung, die Sie in Ihrem Projekt treffen, während ein Projekt auf einer anderen Plattform das Rätsel löst und mit dem belastbaren Datum weiterarbeitet, ohne dass Sie davon auch nur erfahren, geschweige denn die Korrektur Jahre nach Ihrer Projektlaufzeit noch einpflegen können.
Warum sollte ich in meinem Projekt Transparenz schon von Anfang an riskieren?
Das dürfte die härteste Frage sein, die Projekte im Moment davon abhält, sich der eröffneten Ressource bereits zu bedienen. Die Alternative ist die Ressource, die bis zum Publikationstermin gegen Projektende nur unter Passwörtern dem Team zugänglich ist. Kein Konkurrenzprojekt kann Ihnen in der verdeckten Arbeit an Ihrer Plattform Befunde wegschnappen, so die Theorie. Auch sieht niemand, wo Sie erst einmal Fehler machten, die Sie erst im Verlauf korrigierten. Niemand erfasst, was Hilfskräfte eingaben und was dagegen Sie als Projektleiter verantworten – so die Vorteile des intransparenten Arbeitens auf einer Plattform, die erst am Projektende online geht und die keinen Blick in die Versionsgeschichten der Datensätze zulässt geschweige denn in die tägliche Projektarbeit.
Die transparente Forschung, zu der das FactGrid einlädt, bietet indes ganz eigene Sicherheiten: Wenn Sie bahnbrechend ein bestimmtes Dokument auffinden und einen bestimmten Zusammenhang herstellen, dann ist der Editiervorgang, mit dem Sie den Datensatz mit Aussagen bestücken, Aussage um Aussage datiert und jeweils mit Ihrem Namen verbunden. Macht morgen jemand im selben Archiv dieselbe Entdeckung, werden Sie im FactGrid nachweisbar und fälschungssicher notiert haben, dass Sie den Zusammenhang schon einen Tag zuvor öffentlich zugänglich machten.
Die kollektive Plattform spricht im selben Moment die Einladung zur Kooperation aus. Machen Sie anderen Teams klar, woran Sie arbeiten und erlauben Sie noch auf Ihrer Plattform die Kontaktaufnahme mit Ihnen!
Die Risiken des vermeintlich sicheren und erst am Ende der Projektzeit online gehenden Internetauftritts sind gravierend: Die Zeit für einen Austausch mit den Nutzern ist mit der finalen Publikation abgelaufen. Der Internetauftritt erfolgt in den letzten Wochen Ihres Projektes, währen alle anderen letzten Arbeiten laufen und für konzeptionelle Änderungen kein Raum mehr bleibt. Ist überhaupt kein Digital Humanities-Part in der Forschung einkalkuliert, so bleibt unklar, was mit den Daten noch geschehen soll, die Mitspieler in Word-Dateien, Excel-Listen oder eigenen Softwarelösungen ganz für sich sammelten – sie noch irgendwo einzupflegen, hat niemand mehr die Kraft. Man kann nur noch hoffen, dass Leser der abschließenden Buchpublikation in dieser alle Fußnoten auf Korrekturen hin durchkämmen, die im öffentlichen Informationsstand nötig werden und diese dann in allen Bibliothekskatalogen und in den verschiedenen Wikipedia-Projekten durchführen. Das Risiko sind hier Bücher, die an der kollektiven Datengrundlage vorbeigehen und DH-Projekte, die nach ihrer Publikation mangels weiterer Pflege in wenigen Monaten veralten.
Die Zukunft sollte darin liegen, dass wir die Datenlage, derer wir uns selbst in der Forschung bedienen, eigenverantwortlich bearbeiten können. Um dies wiederum ohne Gefahr der Aufgabe wichtiger Befunde tun zu können, müssen wir es Forschern erlauben, ihre Forschungsleistung transparent und zitierbar sichtbar zu machen. Hierfür ist Wikibase besser als jeder andere Software ausgerüstet.
Wie nutze ich das FactGrid konkret?
Das FactGrid hat keine unsichtbare Tiefenschicht. Jeder kann die Datenbank befragen und die Abfragen bieten dabei eingeloggten Benutzern dieselben Antworten wie fremden. Alle Datensätze sind in allen Versionsstufen öffentlich präsent. Der eigene Benutzeraccount bietet beim puren Auslesen von Daten nur den Vorteil, dass Nutzer nun die Software auf die eigene Sprache umstellen können.
Wer eigene Daten einspeisen und mit ihnen auf der Plattform arbeiten will, benötigt dagegen einen Account. Diese werden unter Klarnamen von den Administratoren vergeben. Die Software bietet ein Link zur Account-Anforderung. Wir vergeben ansonsten Accounts auf (Email) Anfrage. Projektleiter erhalten administrative Zugänge, mit denen sie selbst Benutzerkonten vergeben können.
Einmal eingeloggt kann man sowohl Daten in Massen eingeben wie an beliebiger Stelle Datenkorrekturen vornehmen. Alle Eingaben werden an den Benutzer-Account gebunden, der sie tätigt, und können von jedem anderen zurückgenommen werden, was wiederum als exakt diese Rücknahme namentlich dokumentiert und mit einem Zeitstempel versehen wird – für eingeloggte und nicht eingeloggte Benutzer gleichermaßen sichtbar.
Wer an einem komplexeren Projekt arbeiten will —
- das kann die persönliche Familienforschung sein,
- das kann eine einzelne Visualisierung im Rahmen einer Seminararbeit sein,
- das kann genauso gut eine Eingabe von Tausenden von Datensätzen in einem auf mehrere Jahre laufenden Forschungsprojekt mit mehreren Mitarbeitern sein
— ist gut beraten, noch bei der Account-Eröffnung den Austausch mit der Plattform zu suchen. Eine Kooperationsvereinbarung kann dem eigenen Projekt Rückhalt gegenüber Geldgebern geben; doch kann auch einfach nur ein Blogbeitrag mit einer Projekteröffnung interessant sein. In jedem Fall sollten andere auf der Plattform von Ihnen wissen. Spannend wird die kollektiven Datenbank, wo man die Vorarbeiten anderer nutzt und Mitspieler aus anderen Projekten anregt, gute Modelle zu übernehmen. Nötig ist die Abstimmung nicht; praktisch aber trägt sie zur Verbreitung der eigenen Arbeit bei – zu Suchanfragen, die man selbst so schnell nicht zu formulieren weiß, zu Visualisierungen, an die man nicht dachte, zu Hilfe, wo man sie benötigt.
Die Software verspricht eine neugierige Nutzung im breiten Netz und dieses Netz sollte man mit Forschung ansprechen.

One Reply to “FactGrid FAQ – Warum sollte ich das FactGrid für die eigene Forschung nutzen?”